|
인간의 인지 방식을 모방해 이미지 변화를 이해하고, 시각적 일반화와 특정성을 동시 확보할 수 있는 인공지능 기술이 국내에서 개발됐다.
이 기술은 인공지능이 의료영상 분석과 자율주행, 로보틱스 등 분야에서 이미지를 이해해 객체를 분류·탐지하는 데 활용될 수 있을 것으로 기대된다.
KAIST는 전기및전자공학부 김준모 교수 연구팀이 변환 레이블(transformational labels) 없이 스스로 변환 민감 특징을 학습할 수 있는 시각 인공지능 모델 ‘STL(Self-supervised Transformation Learning)’을 개발했다고 13일 밝혔다.
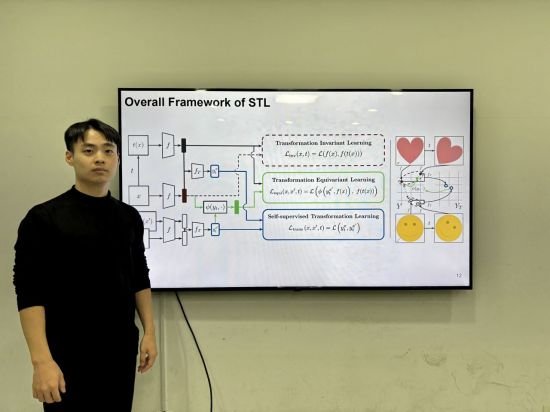
STL은 스스로 이미지 변환을 학습해 이미지 변환의 종류를 인간이 직접 알려주면서 학습하는 기존 방식보다 시각 정보 이해 능력이 높다.
또 기존 방법론으로 학습한 모델이 이해할 수 없는 세부 특징도 학습해 기존 방법 대비 최대 42% 높은 성능을 나타낸다.
가령 컴퓨터 비전에서 이미지 변환을 통한 데이터 증강으로 강건한 시각 표현을 학습하는 방식은 일반화 능력을 갖추는 데 효과적이지만, 변환에 따른 시각적 세부 사항을 무시하는 경향을 보여 범용 시각 인공지능 모델로서는 한계가 있다.
하지만 STL은 변환라벨 없이 변환 정보를 학습할 수 있도록 설계돼 라벨 없이 변환 민감 특징을 학습할 수 있고, 기존 학습 방법보다 학습 복잡도를 유지하면서 최적화된 학습이 가능하다.
실제 실험 결과 STL은 정확하게 객체를 분류하고, 탐지 실험에서 가장 낮은 오류율을 기록했다.
또 STL이 생성한 표현 공간은 변환의 강도와 유형에 따라 명확히 군집화돼 변환 간 관계를 잘 반영하는 것으로 나타났다.
김준모 교수는 "STL은 복잡한 변환 패턴을 학습한 후 이를 표현 공간에서 효과적으로 반영하는 능력으로 변환 민감 특징 학습의 새로운 가능성을 제시했다”며 "라벨 없이도 변환 정보를 학습할 수 있는 기술은 다양한 인공지능 응용 분야에서 핵심적인 역할을 하게 될 것”이라고 말했다.
한편 KAIST 전기및전자공학부 유재명 박사과정이 제1 저자로 참여한 이번 연구 결과(논문)는 최고 권위 국제 학술지‘신경정보처리시스템학회(NeurIPS) 2024’에서 이달 발표될 예정이다.
대전=정일웅 기자 jiw3061@asiae.co.kr
<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제 무단전재 배포금지> | 

 이메일
이메일 카카오톡
카카오톡 라인
라인 밴드
밴드 X(트위터)
X(트위터) 페이스북
페이스북
 등록안내
등록안내 등록안내
등록안내
